


How to create a chatbot with a history-saving option using LangChain and ChatOllama in 10 minutes

LangChain offers a robust framework for building chatbots powered by advanced large language models (LLMs). Its modular design and seamless integration with various LLMs make it an ideal choice for developers seeking to create intelligent conversational agents. In this guide, we’ll focus on crafting a streaming chatbot using LangChain's ChatOllama.
This chatbot not only streams real-time responses for a smooth and interactive user experience but also saves the conversation history, allowing it to maintain context across multiple interactions. This ability to retain context makes the chatbot smarter and more effective in handling complex multi-turn dialogues. By the end of this guide, you'll have a chatbot that’s ready to handle dynamic conversations.
To ensure clarity, we’ll break the code into manageable sections and explain each step in detail, making it easy for you to follow along and implement. Let’s dive in!
1. Importing the necessary libraries
from langchain_ollama import ChatOllama
from langchain.schema import SystemMessage, AIMessage, HumanMessageWe start by importing the required modules:
ChatOllama: Enables interaction with the Llama language model.SystemMessage,AIMessage, andHumanMessage: Represent different types of messages in the chat, helping maintain structured conversation history.
2. Setting up the chat model
llm = ChatOllama(
model="llama3.2", # replace it with model you want to use
)Here, we initialize the ChatOllama instance with the model version "llama3.2". You can replace this with the specific version or configuration of the Llama model you want to use.
3. Initializing the conversation history
chat_history = []
system_message = SystemMessage(content="You are a helpful AI assistant.")
chat_history.append(system_message)chat_historyis a list used to store the flow of the conversation.The
SystemMessageprovides initial instructions to the chatbot. This ensures the assistant knows its role (e.g., "You are a helpful AI assistant.").
4. Interactive chat loop
while True:
query = input("You: ")
if query.lower() == "exit":
break
chat_history.append(HumanMessage(content=query))This loop allows for real-time interaction:
The user’s input is captured with
input().Typing
"exit"ends the session.Each user query is stored as a
HumanMessageinchat_history.
5. Streaming AI responses
response = ""
print("AI: ", end="", flush=True)
for chunk in llm.stream(chat_history):
token = chunk.content
response += token
print(token, end="", flush=True)The chatbot streams its responses using
llm.stream(chat_history), which returns chunks of the reply as they are generated.Each chunk (
token) is printed immediately for a seamless experience.The full response is reconstructed by appending tokens to the
responsevariable.
6. Saving AI responses to history
print()
chat_history.append(AIMessage(content=response))Once the chatbot completes its response:
The entire reply is added to
chat_historyas anAIMessage.This ensures that context is preserved for future interactions.
7. Displaying chat history
print("----Chat History----")
print(chat_history)After exiting the loop, the script displays the entire conversation history. Each message is stored as a structured object (SystemMessage, HumanMessage, AIMessage), making it easy to save or analyze.
Features of the chatbot
Streaming Responses: Provides real-time output for a smooth conversational experience.
Context Retention: Saves all messages in
chat_historyto maintain context across turns.Customizable LLM: You can choose the desired Llama model or fine-tune it for specific use cases.
Interactive and Structured: The chatbot processes user inputs and replies in a structured format, ensuring clear communication.
Potential Applications
Real-time conversational AI tools.
Educational platforms for interactive learning.
Customer support systems with conversational memory.
Research prototypes for exploring multi-turn conversations.
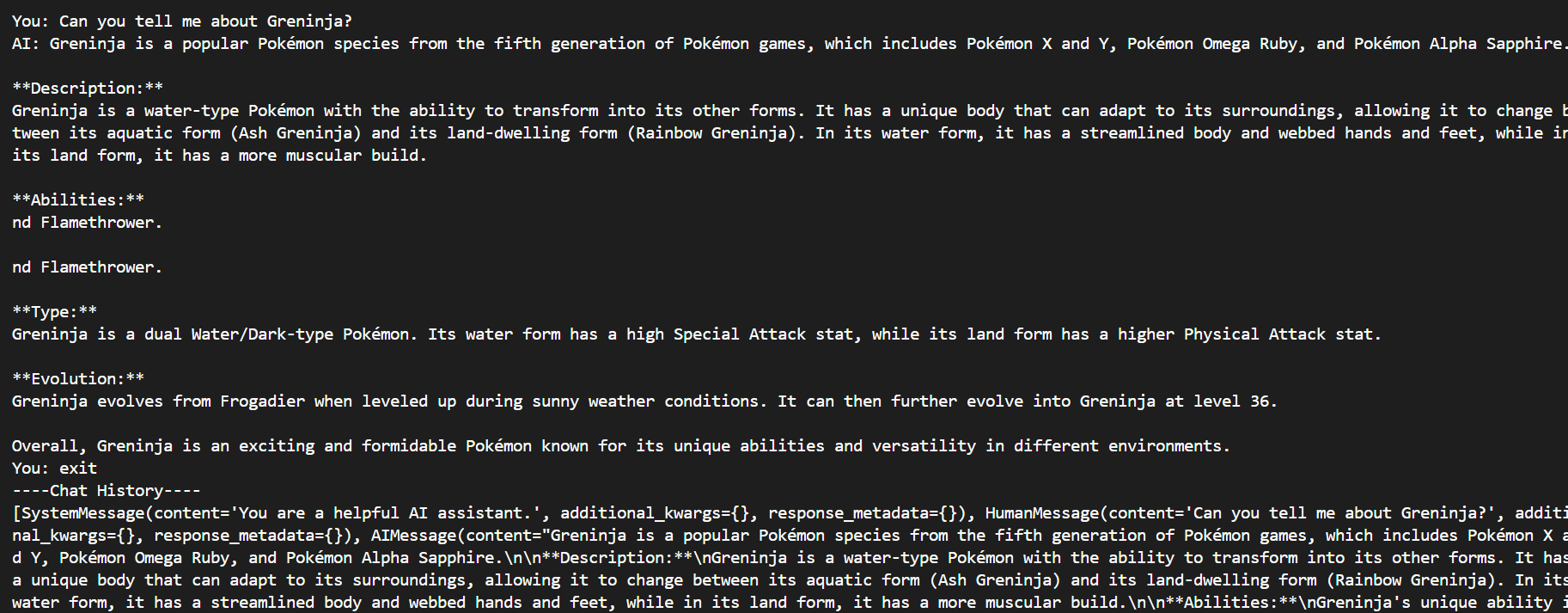
Challenge while creating the chatbot
In the example above, our chatbot exhibits a phenomenon known as hallucination—where the AI generates inaccurate or misleading information. For instance, it mistakenly identifies Greninja as a Generation Five Pokémon when it is actually from Generation Six.
To address such inaccuracies, it's important to remain cautious when relying on AI-generated responses. If you want to improve the model's accuracy and reduce hallucination, especially for domain-specific knowledge, you can use a technique called Retrieval-Augmented Generation (RAG).
RAG enhances the model by combining its language generation capabilities with an external knowledge base. This allows the chatbot to retrieve relevant, factual information dynamically, ensuring more accurate and reliable responses while reducing hallucination.
Conclusion
This guide demonstrates how to create a streaming chatbot with LangChain and ChatOllama while preserving conversation history. With these capabilities, you can build dynamic, context-aware applications tailored to a variety of use cases, such as customer support, education, or interactive tools. To reduce inaccuracies or hallucinations, consider using Retrieval-Augmented Generation (RAG) to integrate external knowledge sources, ensuring more accurate responses.
References
LangChain Master Class for Beginners 2024 by Code with Brandon
Watch the video here
LangChain Documentation – How To Guide
Read the guide here
LangChain Integration with Ollama
Explore the integration here